画像ファイルからテキストを抽出するOCR処理は、データの取り扱いや作業の効率化において非常に便利です。しかし、大量のファイルを手動で処理するのは時間がかかる上に、ミスの可能性もあります。そこで今回は、Google Apps Scriptを用いて、Googleドライブ上の特定のフォルダに画像ファイルをコピーするだけで自動的にOCR処理を行い、結果をテキストファイルとして別のフォルダに保存するスクリプトを紹介します。
スクリプトの概要
本スクリプトは、Googleドライブ上の特定のフォルダに配置された画像ファイルを対象に、Googleドキュメントを用いて日本語のOCR処理を行います。OCR結果はテキストファイルとして別のフォルダに保存され、元のファイルは「処理済み」のフォルダへ移動します。これにより、手動でファイルを開き、OCR処理を行い、結果を保存するという一連の作業を自動化することができます。
Googleドライブにフォルダを作成する
まずは、GoogleアカウントでGoogleドライブにログインし、「新規」>「新しいフォルダ」で必要なフォルダを作成しておきます。必要なのは、
- OCR処理を行いたい画像をアップロードするフォルダ
- ドキュメントファイルを出力するフォルダ
- テキストファイルを出力するフォルダ
- 処理済みの画像ファイルを移動するフォルダ
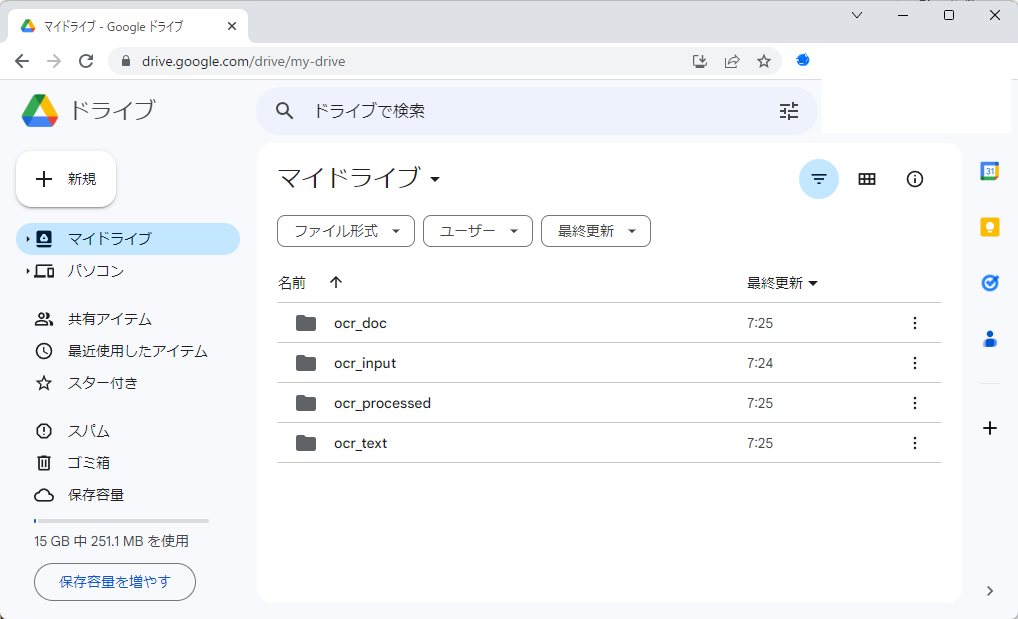
です。以下の画像では、それぞれ「ocr_input」「ocr_doc」「ocr_text」「ocr_processed」という名前で作成していますが、自分が分かりやすい名前なら何でもかまいません。
スクリプトの設定と実行
Google Apps Scriptのセットアップ
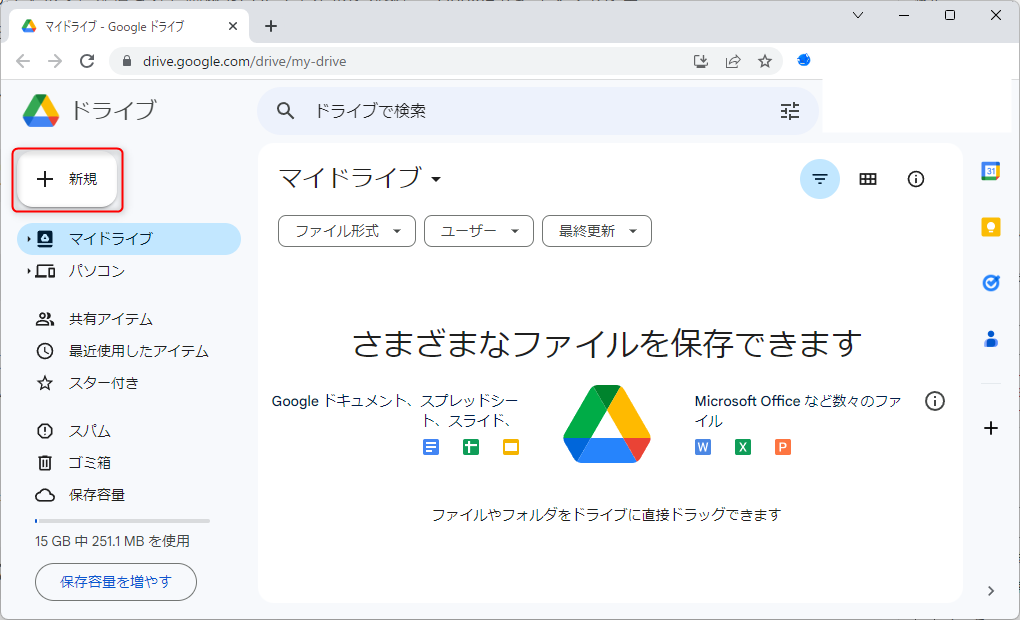
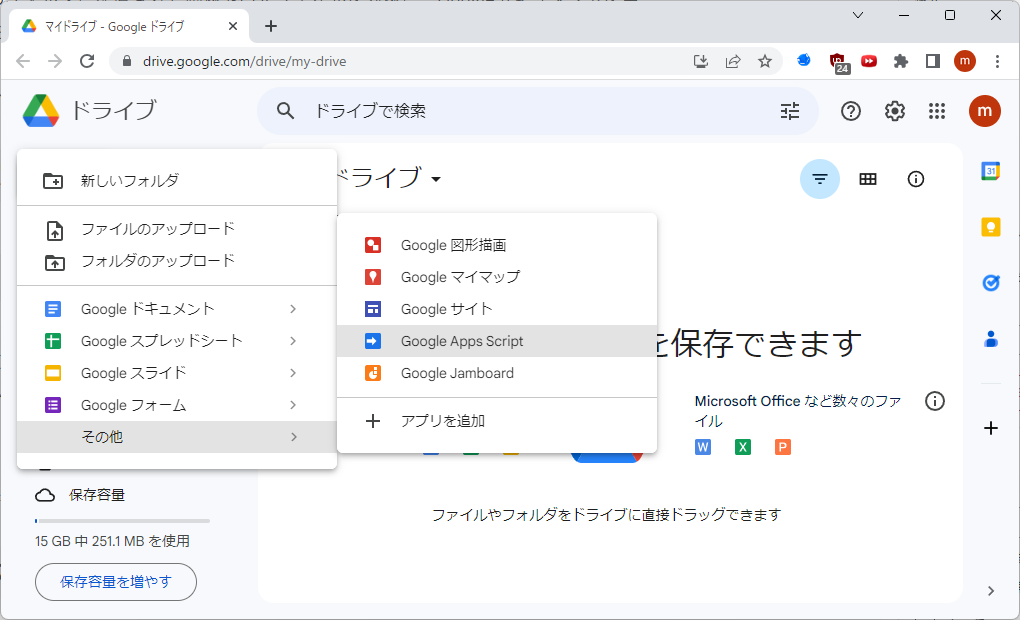
次に、「新規」→「その他」→「Google Apps Script」を選択して新しいプロジェクトを作成します。すると、別のタブでApps Scriptの「無題のプロジェクト」が開きます。
スクリプトの導入
プロジェクトが開くと、以下のようなコードが表示されます。このコードは、必要ないので削除します。
function myFunction() {
}そして、以下のスクリプトをコピー&ペーストします。
// フォルダIDとMimeTypeを指定します。
const SOURCE_FOLDER_ID = 'OCR処理したい画像をアップロードするフォルダのID';
const TEXT_FOLDER_ID = 'テキストファイルを出力するフォルダのID';
const DOC_FOLDER_ID = 'Googleドキュメントのファイルを出力するフォルダのID';
const PROCESSED_FOLDER_ID = '処理済みの画像を移動させるフォルダのID';
const SUPPORTED_MIME_TYPES = [MimeType.PNG, MimeType.JPEG, MimeType.GIF, MimeType.BMP];
function ocrFiles() {
let sourceFolder = DriveApp.getFolderById(SOURCE_FOLDER_ID);
let textFolder = DriveApp.getFolderById(TEXT_FOLDER_ID);
let processedFolder = DriveApp.getFolderById(PROCESSED_FOLDER_ID);
let docFolder = DriveApp.getFolderById(DOC_FOLDER_ID);
const options = {
"ocr": true,
"ocrLanguage": "ja",
};
for (let mimeType of SUPPORTED_MIME_TYPES) {
let files = sourceFolder.getFilesByType(mimeType);
while (files.hasNext()) {
let file = files.next();
// ファイルをOCR処理します。
let resource = {
title: file.getName()
};
console.log(file.getName())
let doc = Drive.Files.copy(resource, file.getId(), options);
let text = DocumentApp.openById(doc.id).getBody().getText();
console.log(text);
// docをDOC_FOLDER_IDのフォルダに移動します。
DriveApp.getFileById(doc.id).moveTo(docFolder);
// テキストファイルを保存します。
let textFileName = file.getName().replace(/\.[^.]*$/, '') + '.txt';
textFolder.createFile(textFileName, text, MimeType.PLAIN_TEXT);
// 処理が完了した画像ファイルを「processed」フォルダに移動します。
file.moveTo(processedFolder)
}
}
}フォルダIDの設定
次に、スクリプトの以下の部分に、最初に作成した各フォルダのIDをコピー&ペーストします。
const SOURCE_FOLDER_ID = 'OCR処理したい画像をアップロードするフォルダのID';
const TEXT_FOLDER_ID = 'テキストファイルを出力するフォルダのID';
const DOC_FOLDER_ID = 'Googleドキュメントのファイルを出力するフォルダのID';
const PROCESSED_FOLDER_ID = '処理済みの画像を移動させるフォルダのID';フォルダIDは、Googleドライブで各フォルダを開いた時、URLの末尾に表示される文字列です。フォルダIDについては、以下の記事で詳しく解説しています。
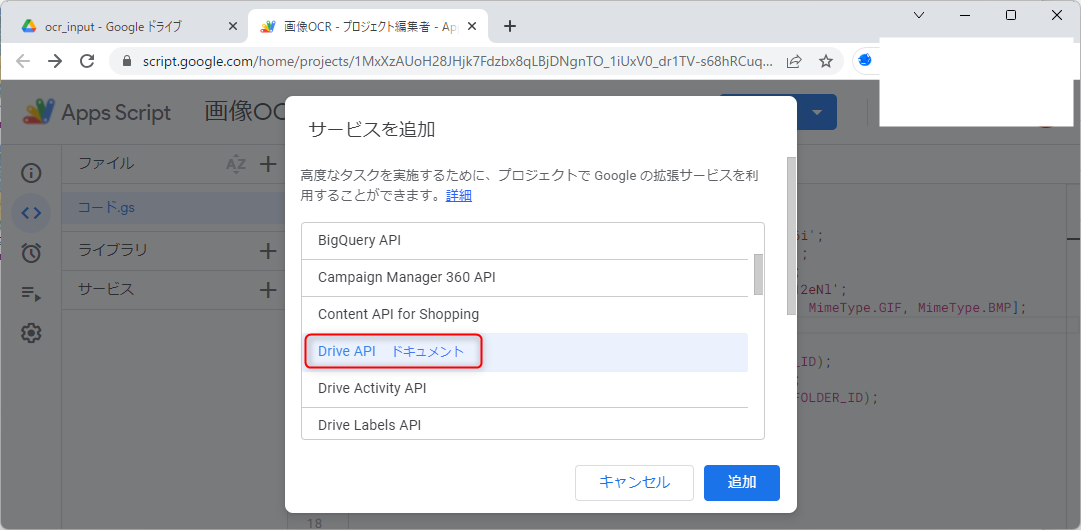
ドライブAPIの追加
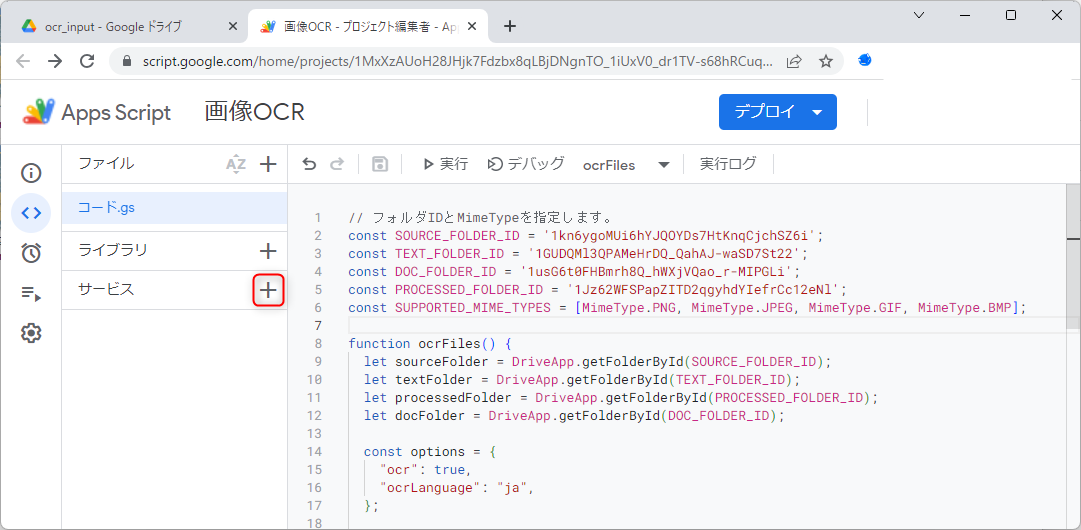
このコードでは「Drive API」を利用しているので、「サービス」をクリックして「サービスの追加」ダイアログを開き、「Drive API」を選択して「追加」を押しましょう。
プロジェクト名の変更と保存
プロジェクト名「無題のプロジェクト」をクリックすれば、変更ダイアログが開きます。分かりやすい名前に変更しておきましょう。その下にあるフロッピーディスクのアイコンを押して保存すれば、実行できるようになります。
OCR処理する画像のアップロード
Googleドライブで、OCR処理したい画像ファイル(PNG・JPG・GIF・BMPのいずれか)を作成したアップロード用フォルダに保存してください。複数処理できますが、まずは試しに1枚だけ配置してみるのがいいでしょう。
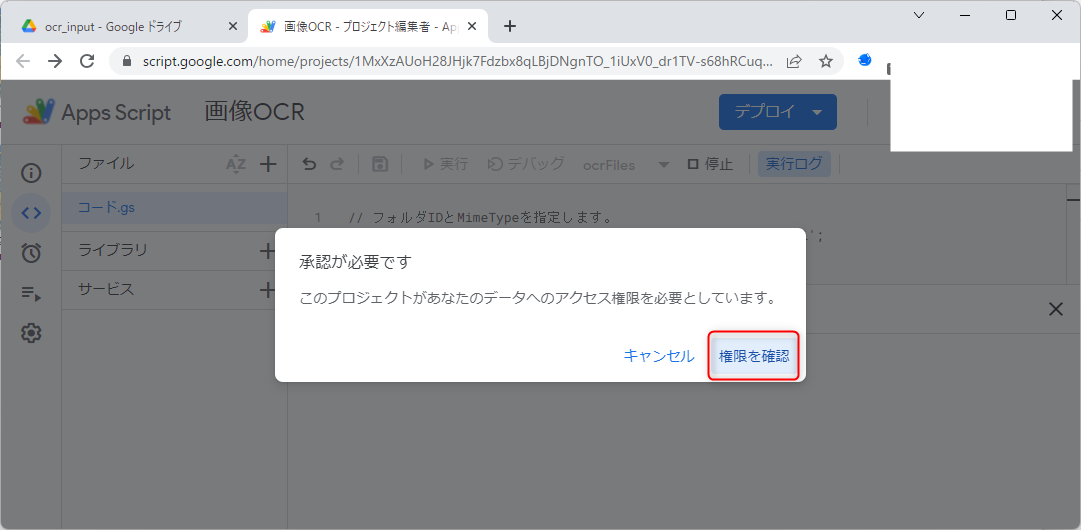
スクリプトの実行
Apps Scriptのページに戻って「実行」を押すと、初回時のみ以下のようなダイアログが表示されます。これは、不正なアプリによりGoogleドライブやドキュメントのデータにアクセスされることを防ぐためのものです。
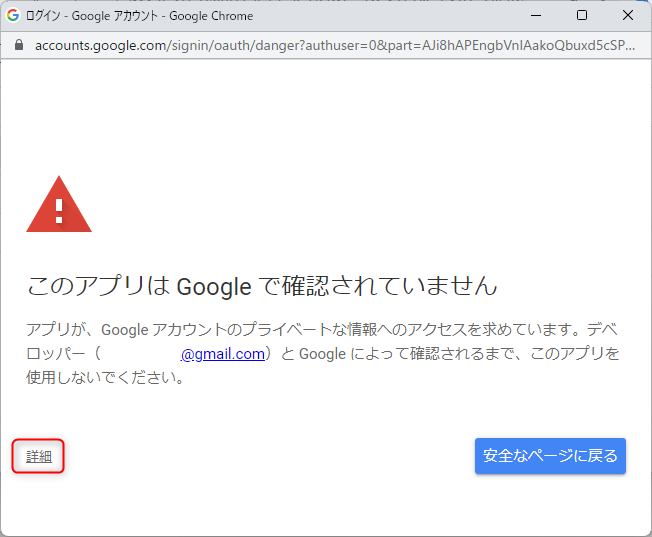
次のダイアログでは、左下に小さく表示された「詳細」をクリックします。
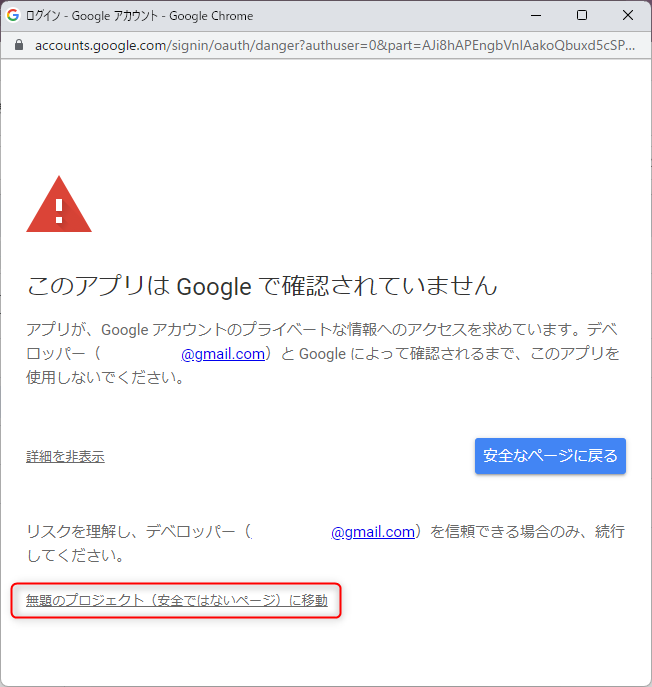
自分のアカウントが表示されていることを確認し、「プロジェクト名(安全ではないページ)に移動」をクリックします。
「許可」をクリックします。
これでスクリプトが実行され、実行ログで動作が確認できます。エラーが発生しなければ、ドライブにドキュメントファイルとテキストファイルが生成されているはずです。
ドキュメントファイルは、ダブルクリックするとGoogleドキュメントで開きます。テキストファイルは、ドキュメントファイルの内容をプレーンテキストにしたものです。ドキュメントファイルの保存が不要な場合は、削除するようスクリプトを変更してもいいでしょう。
画像ファイルを複数アップロードして実行すれば、順次OCR処理が実行されます。ただし、Apps Scriptの実行時間は、無料ユーザーなら6分に制限されています。そのため、大量のファイルを処理しようとしても、途中で処理が止まってしまいます。再度「実行」をクリックすれば、まだ「処理済みフォルダ」に移されていない画像ファイルの処理を継続することは可能です。
「トリガー」を使った自動実行
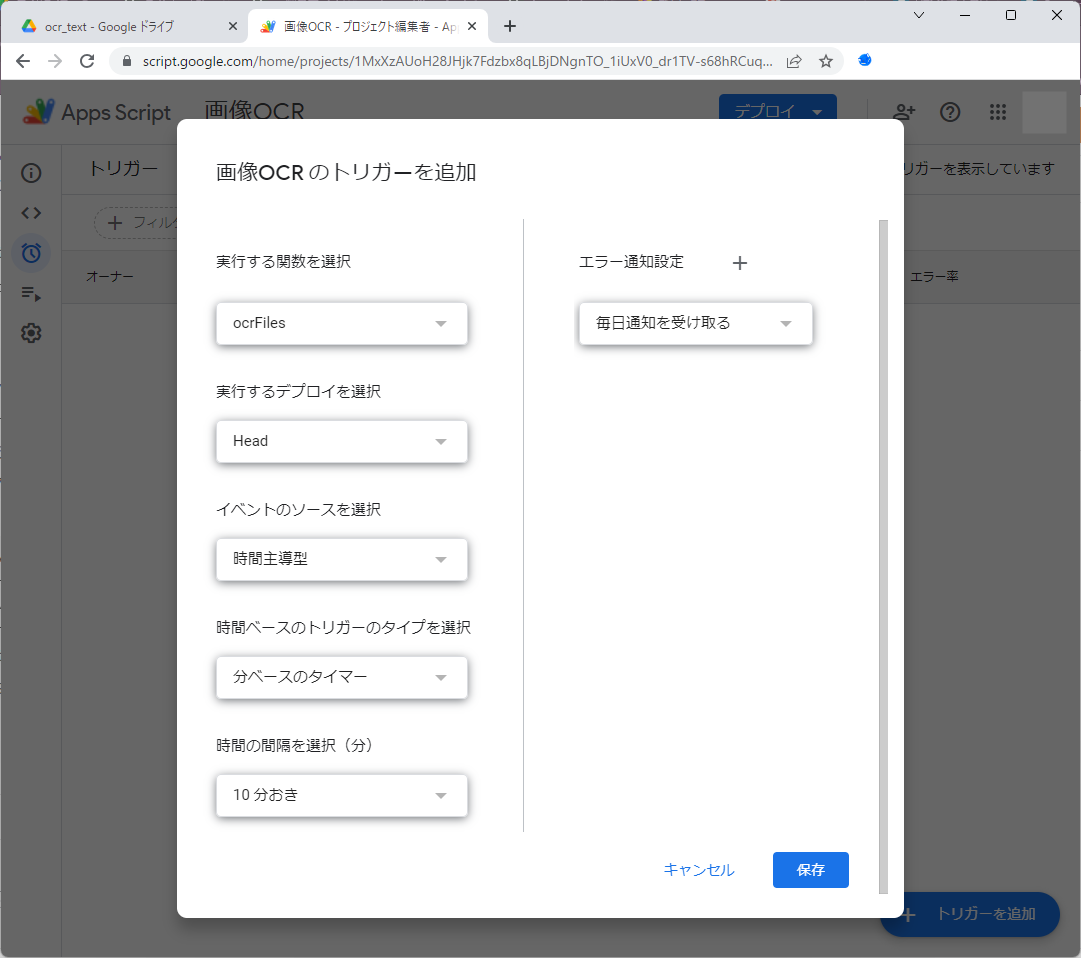
手動で再実行するのは面倒ですが、自動で再実行させる方法があります。左側のストップウォッチアイコンをクリックして「トリガー」を開きましょう。以下のように登録しておけば、10分毎にアップロード用フォルダーを調べ、画像があればOCR処理が実行されます。これで、OCR処理したい画像をアップロードしておきさえすれば、自動で処理させることが可能になりました。ただし、Googleドライブには容量の制限がありますし、Apps Scriptにも実行時間の制限があるので、あまりに大量の画像を一度にOCR処理しようとすると、問題が出る可能性がある点には注意が必要です。
利用上の注意点
- このスクリプトはGoogleドライブの使用量に影響します。大量のファイルを処理する場合は、ドライブの空き容量を確認してから使用してください。
- Google Apps Scriptには一日の実行時間の上限があります。大量のファイルを一度に処理する場合は、この制限に注意してください。
スクリプトの解説
スクリプトの内容を理解しなくても使えますが、興味がある方のために、上記スクリプトの流れを簡単に解説します。
フォルダIDとMimeTypeの指定
スクリプトの冒頭部分では、ソースとなるフォルダ、テキストを保存するフォルダ、ドキュメントを保存するフォルダ、処理済みファイルを保存するフォルダのIDを指定しています。また、OCR処理を行う対象のMimeType(ファイルの種類)も指定しています。
OCR処理のオプション
次に、OCR処理のオプションを指定します。ここではOCRを有効にし、言語を日本語に設定しています。
ファイルの取得と処理
ここでは、指定したMimeTypeのファイルをソースフォルダから取得し、それぞれに対してOCR処理を行います。OCR処理はGoogleドキュメントを使用して行います。
テキストの抽出と保存
OCR処理が完了したら、その結果をテキストとして抽出し、指定したフォルダにテキストファイルとして保存します。
ファイルの移動
最後に、処理が完了したファイルを「処理済み」のフォルダに移動します。これにより、同じファイルが何度も処理されることを防ぎます。
まとめ
本記事では、Google Apps Scriptを用いてOCR処理を自動化するスクリプトを紹介しました。このスクリプトを活用すれば、OCR処理が必要なファイルを特定のフォルダにドロップするだけで、自動的にテキスト抽出と保存が行われ、作業の効率化が図れます。ぜひ一度試してみてください。
コメント